โตชิบาสร้าง AI แปลงเสียงเป็นข้อความแบบเรียลไทม์ พลิกโฉมการทำงานด้วยสมองกลอัจฉริยะ

อย่างไรก็ตาม หลายบริษัทยังจำเป็นต้องมีคนทำงานจิปาถะ อย่างเช่นจดบันทึกการประชุม หรือถอดความจากการบันทึกเสียง แม้ว่าในปัจจุบันจะมีระบบ AI และซอฟต์แวร์แปลงคำพูดเป็นตัวอักษรวางขายในตลาดแล้ว การถอดเสียงพูดให้เป็นข้อความอย่างถูกต้องแม่นยำยังคงต้องอาศัยการทำงานของมนุษย์อยู่เราจะช่วยแก้ปัญหาตรงจุดนี้ และร่วมสร้างสังคมที่คนสามารถทำงานได้ง่ายขึ้นได้อย่างไร? โตชิบามีคำตอบที่มาพร้อมระบบสมองกลอัจฉริยะ AI รับรู้เสียงพูดที่พัฒนาขึ้นล่าสุด นายทาอิระ อาชิคาวะ และนายฮิโรชิ ฟูจิมูระ คือสองนักพัฒนาจากศูนย์วิจัยและพัฒนาของโตชิบา คอร์ปอเรชั่น ซึ่งเป็นผู้ที่พัฒนา AI ดังกล่าว พวกเขาจะเล่าถึงความเป็นมาของการใช้สมองกลในการจดจำคำพูด รวมไปถึงความสำเร็จที่เกิดขึ้นระหว่างการทำงานชิ้นนี้
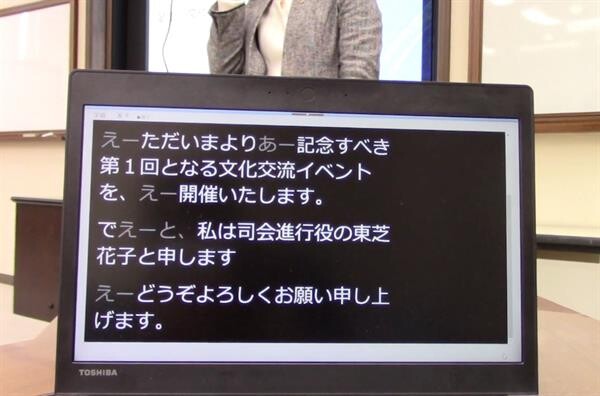
ถอดความอย่างราบรื่น พร้อมแสดงผลข้อมูลที่อ่านง่ายและรวดเร็ว
โตชิบามีประสบการณ์ทำงานในแวดวงการวิเคราะห์สื่อ หรือ Media Intelligence มายาวนาน ซึ่งเป็นสาขาอาชีพที่ใช้ประโยชน์จากเสียงและภาพที่ผ่านการประมวลข้อมูลมาแล้ว และพื้นฐานที่บริษัทได้สั่งสมมาจากการทำงานในแวดวงนี้เอง ที่มีบทบาทสำคัญในการสร้าง AI รับรู้เสียงตัวนี้
โตชิบาเริ่มพัฒนา AI รับรู้เสียงพูดในปี ค.ศ. 2015 ซึ่งในขณะนั้นมีการตื่นตัวเรื่องความสำคัญการเข้าถึงข้อมูลเกิดขึ้นทั่วโลก โดยเฉพาะการสร้างสภาพแวดล้อมที่ช่วยให้คนหูหนวกหรือบกพร่องทางการได้ยิน สามารถเข้าถึงข้อมูลและส่งมอบข้อมูลต่าง ๆ ได้ ด้วยความเชื่อมั่นในการส่งเสริมความหลากหลายและการสร้างความเป็นอันหนึ่งอันเดียวกันในสถานที่ทำงาน โตชิบาจึงได้ริเริ่ม "Universal Design (UD) Advisor System" หรือ "ระบบที่ปรึกษาการออกแบบสากล" ขึ้นตั้งแต่ปี ค.ศ. 2007 เพื่อช่วยให้พนักงานที่มีความทุพพลภาพสามารถร่วมเสนอความคิดเพื่อช่วยพัฒนาผลิตภัณฑ์ได้ และยังได้พัฒนาสินค้าและบริการที่มีการออกแบบสากลขึ้นมาอีกมากมายในช่วงหลายปีที่ผ่านมา
นายอาชิคาวะ เผยว่า "ตอนที่เราสัมภาษณ์ผู้ที่มีภาวะบกพร่องทางการได้ยินจากโครงการ UD Advisor System เราพบว่าพวกเขาอยากมีส่วนร่วมในการประชุม หรือการเรียนเล็คเชอร์แบบเรียลไทม์ (Real-time) ไม่ใช่แค่ตามอ่านเอกสารจากการถอดเทปภายหลัง เราจึงพยายามที่จะสร้างฟังก์ชันที่สามารถแสดงคำบรรยายที่อ่านเข้าใจง่าย ๆ ได้แบบทันที เพื่อช่วยผู้บกพร่องทางการได้ยินในการรวบรวมและนำเสนอข้อมูล โดยเราเน้นหน้าที่หลัก 2 ประการคือ การขยายช่องทางการเข้าถึงข้อมูลสำหรับผู้บกพร่องทางการได้ยิน และการเพิ่มประสิทธิภาพการทำงานของระบบ ดังนั้น การพัฒนา AI รับรู้เสียงพูดของเราจึงเริ่มขึ้นจาก 2 ประการนี้"
เทคโนโลยีเบื้องหลังความสำเร็จของระบบรับรู้เสียงพูด
หากคุณเคยพยายามถอดเทปเสียง คุณคงทราบดีว่า ขณะที่คุณพยายามจดรายละเอียดของการสนทนา ไม่ว่าจะระหว่างการประชุมหรือการบรรยาย ข้อความที่ได้มักจะยุ่งเหยิง อ่านยาก แถมยังมีรายละเอียดที่ไม่สำคัญเข้ามาเป็นอุปสรรคในการจดบันทึกเนื้อหาข้อมูลที่ถูกต้อง โดยเฉพาะพวกคำเติม (filler words) เช่น "เอ่อ" และ "อืม" หรือคำที่แสดงการตอบรับหรือเห็นด้วย ที่ไม่ได้มีความสำคัญอะไรกับเนื้อหาหลัก
เทคโนโลยี AI รับรู้เสียงพูดที่โตชิบาพัฒนาขึ้นนี้ สามารถรับรู้คำพูดด้วยความแม่นยำสูง และยังสามารถรับรู้ถึงพวกคำเติม และคำที่แสดงความลังเลได้เช่นกัน นี่ถือเป็นฟังก์ชันสำคัญในการปรับปรุงประสิทธิภาพการทำงานของระบบ อัลกอริทึม (Algorithm) นั้นเปรียบเสมือนแกนกลางของ AI และทีมนักพัฒนาก็ได้ทดลองหลากหลายวิธีการเพื่อเพิ่มประสิทธิภาพการทำงานของมัน
นายฟูจิมูระ เล่าว่า "ในช่วงแรกพวกเราเจอแต่ทางตัน เพราะไม่ว่าเราจะทำอย่างไรก็ไม่สามารถเพิ่มประสิทธิภาพความแม่นยำของการรับรู้เสียงได้ เพราะเป้าหมายหลักของเราคือการสร้างระบบที่ผู้ใช้งานสามารถใช้ได้อย่างสะดวกรวดเร็ว และด้วยโปรแกรมยอดนิยมอย่าง LSTM(*1) และ CTC(*2) เราได้พยายามสอน AI เกี่ยวกับลักษณะการพูด เช่น คำเติม และคำที่แสดงความลังเล ซึ่งเป็นลักษณะเฉพาะของการพูดของมนุษย์"
(*1) LSTM (Long Short-term Memory) คือโมเดลหนึ่งของ RNN (Recurrent Neural Network) ซึ่งมีโครงข่ายแบบวนซ้ำซ่อนอยู่ในเลเยอร์ จึงสามารถเรียนรู้ความสัมพันธ์แบบพึ่งพาระยะยาว ซึ่งยากสำหรับ RNNs แบบเดิม
(*2) CTC (Connectionist Temporal Classification) หรือ การจำแนกการเชื่อมต่อชั่วคราว คือหนึ่งในวิธีการฝึก RNN ให้แก้ปัญหาเมื่อความยาวของข้อมูลแบบลำดับแตกต่างกันในระหว่างการป้อนข้อมูล โดยการแนะนำลักษณะที่ถือเป็นโมฆะ และการปรับฟังก์ชันที่สูญเปล่า
ระบบรับรู้เสียงพูดตั้งแต่อดีตจนถึงปัจจุบัน จะทำงานโดยวิเคราะห์รูปแบบคลื่นเสียงและจำแนกออกมาว่า จุดนี้คือเสียง "อะ" จุดนี้คือเสียง "อิ" เช่นนี้ไปเรื่อย ๆ แต่คำเติม และคำที่แสดงความลังเล มีรูปแบบแตกต่างกันมากมายนับไม่ถ้วน หากระบบจะเรียนรู้ทีละอันก็ต้องใช้เวลายาวนานในการพัฒนา
นายฟูจิมูระ เล่าต่อว่า "เราใช้ LSTM ในการตรวจจับข้อมูลว่า 'นี่คือลักษณะคำเติมนะ' หรือ 'นี่คือเสียงเวลาคนแสดงความลังเล' เป็นโมเดลทางสถิติ จากนั้นจึงใช้ CTC เข้ามาสอนให้ AI เรียนรู้ตามโมเดลนั้น ด้วยวิธีนี้ระบบสมองกลจึงสามารถตรวจจับหลากหลายรูปแบบของคำเติม และคำแสดงความลังเลเช่นกัน"
"แน่นอนว่ามันยังมีช่องทางในการพัฒนาอีกมากมายสำหรับเทคโนโลยีนี้ เพื่อให้เราสามารถนำเสนอระบบรับรู้เสียงพูดที่มีความแม่นยำสมบูรณ์แบบได้ ณ ตอนนี้ AI ของเราสามารถรับรู้เสียงพูดได้ 3 ภาษา ได้แก่ ภาษาญี่ปุ่น ภาษาอังกฤษ และภาษาจีน ซึ่งเรามีเป้าหมายที่จะสร้างสภาพแวดล้อมที่ผู้พูดภาษาต่าง ๆ สามารถสื่อสารกันได้อย่างราบรื่นไร้อุปสรรค นั่นคือสิ่งที่เราวาดฝันไว้ในตอนที่เราเริ่มพัฒนา AI นี้ ซึ่งมันเป็นภาพที่เราเคยเห็นแต่ในนิยาย sci-fi หรือในหนังสือการ์ตูน ซึ่งเราอยากทำให้มันกลายเป็นความจริง"
นี่คือวิธีการที่สมองกลถูกพัฒนาขึ้นจนกลายเป็น AI รับรู้เสียงพูดที่มีความแม่นยำสูง เมื่อทางทีมนักพัฒนามีโอกาสได้ใช้การบรรยายเป็นการทดสอบระบบ พวกเขาพบว่าตัว AI สามารถรับรู้เสียงพูดได้สูงถึง 85% นั่นหมายความว่ามันสามารถรับรู้เนื้อหาข้อมูลในการพูดนั้นได้สูงกว่าปกติโดยไม่จำเป็นต้องอาศัยการเรียบเรียงข้อมูลหรือการเรียนรู้ขั้นสูงใด ๆ และในตอนนี้ เมื่อพวกเขาสามารถเพิ่มประสิทธิภาพความถูกต้องแม่นยำของระบบรับรู้เสียงพูดแล้ว พวกเขาก็กำลังพิจารณาว่าจะนำมันไปใช้กับ AI สำหรับการสื่อสารอีกตัวของโตชิบาที่ชื่อ RECAIUS
พวกเขาพัฒนาแอปพลิเคชันที่มีฟังก์ชันแสดงภาพคำบรรยายแบบเรียลไทม์สำหรับผู้ที่มีความบกพร่องทางการได้ยิน โดยให้ AI แสดงข้อความที่ชัดเจนอ่านง่าย และแสดงคำเติม หรือคำแสดงความลังเลเป็นอักษรที่จางลง นี่เป็นวิธีที่พวกเขาค้นพบว่าง่ายต่อการใช้งานที่สุดหลังจากที่ได้พูดคุยรายละเอียดกับกลุ่มผู้ใช้งาน
นายอาชิคาวะ อธิบายว่า "ในมุมมองของเรา พวกคำเติมอย่าง "เอิ่ม" หรือ "เอ่อ" นั้นไม่ได้มีประโยชน์อะไร แต่สำหรับผู้ที่บกพร่องทางการได้ยิน พวกเขาต้องการที่จะได้รับข้อมูลให้มากที่สุดเท่าที่จะทำได้ เวลาที่พวกเขาอ่านคำบรรยายในขณะที่มองตามการขยับปากของผู้พูด พวกเขาอาจจะรู้สึกไม่สบายใจ ถ้าคำเติม และคำที่แสดงความลังเลพวกนี้ถูกตัดออก เพราะพวกเขาจะรู้สึกว่าสิ่งที่ผู้พูดกำลังสื่อสารนั้นไม่ได้แสดงอยู่ในคำบรรยาย"
"ด้วยเหตุนี้ เราจึงตัดสินใจปล่อยคำเติม และคำที่แสดงความลังเลพวกนี้ไว้ในคำบรรยายด้วย แต่แสดงเป็นอักษรสีจางลงเพื่อให้อ่านเข้าใจได้ง่ายขึ้น แต่ว่าเมื่อเราถอดความออกมาเป็นเอกสารอย่างเป็นทางการ เราจะตัดคำพวกนี้ออกไป เพื่อให้ได้เอกสารที่สั้นและกระชับมากขึ้น"
ประโยชน์ของ AI รับรู้เสียงในภาคการผลิต
ในเดือนมีนาคม 2562 โตชิบาได้ร่วมงานกับบริษัท DWANGO ในการถ่ายทอดสดการประชุมของสมาคมการประมวลผลข้อมูลแห่งประเทศญี่ปุ่นครั้งที่ 81 ผ่านเว็บไซต์ "niconico" โดยวิดีโอการประชุมที่มีคำบรรยายใต้ภาพได้ถูกเผยแพร่ในแบบเรียลไทม์ ซึ่งทำให้พวกเขาวางแผนที่จะใช้งาน AI ตัวนี้ ไม่เฉพาะแค่ในออฟฟิศ แต่ในภาคการผลิตเช่นกัน
"ทุกวันนี้ เทคโนโลยีการรับรู้เสียงพูดไม่ได้ถูกนำมาใช้ในออฟฟิศ หรือสถานที่ทำงานต่าง ๆ มากนัก สำหรับพวกเราแล้ว จะถือเป็นความสำเร็จอย่างยิ่งหากทุกคนเชื่อใจและใช้งานผลิตภัณฑ์ของเรา เหมือนมันเป็นเครื่องมือที่ใช้ในการทำงานทุกวันจนแทบจะลืมไปว่ามันคือ AI รับรู้เสียงพูด ยกตัวอย่างเช่น ขณะที่พวกเราพูดคุยกันอยู่นี้ AI สามารถแปลงคำพูดเราเป็นข้อความที่สละสลวยและใช้ในเอกสารทางธุรกิจได้ทันที และยังระบุได้ชัดเจนว่าผู้พูดแต่ละคนพูดอะไรบ้าง เราหวังว่าจะสามารถสร้าง AI รับรู้เสียงพูด ที่ทั้งสะดวก และพึ่งพาได้แบบนั้น" นายอาชิคาวะ กล่าว
อย่างไรก็ดี เทคโนโลยีรับรู้เสียงพูดยังไม่ได้ถูกนำมาใช้ในฝั่งของภาคการผลิตเท่าไร ทั้งที่มันยังมีความต้องการการบันทึกเสียงแบบแฮนด์ฟรีในโรงงาน โดยเฉพาะในด้านการบำรุงรักษาและการตรวจสอบ ผมจึงคิดว่ามันยังมีช่องทางที่ AI รับรู้เสียงพูดจะสามารถถูกนำมาใช้ในจุดนั้นได้เช่นกัน
"เราหวังว่าเราจะสามารถใช้ความรู้และประสบการณ์ของเราเกี่ยวกับโรงงานการผลิต มาบูรณาการเทคโนโลยีรับรู้เสียงพูดเข้ากับการทำงาน ที่เราสามารถทำเช่นนั้นได้เพราะเราได้ใช้เวลายาวนานในการพัฒนา AI รับรู้เสียงพูด และสั่งสมความรู้เกี่ยวกับการผลิตและโครงสร้างพื้นฐาน 'ทำไมโตชิบาจะต้องสร้างเทคโนโลยีรับรู้เสียงพูดด้วย?' ผมคิดว่านี่คือหนึ่งในคำตอบที่ชัดเจนที่สุด" นายฟูจิมูระ กล่าวสรุป
จากประโยชน์และความเป็นไปได้ในการนำมาใช้งานในรูปแบบต่าง ๆ จึงปฏิเสธไม่ได้เลยว่าซอฟต์แวร์การรับรู้เสียงพูดจะถูกนำมาใช้งานมากขึ้นเรื่อย ๆ ทั้งในสถานที่ทำงานและในไซต์การผลิตในเวลาอีกไม่นาน

ติดต่อเราได้ที่ facebook.com/newswit